목록전체 글 (212)
1. 요즘 파이토치가 많이 나간다 탑티어 학회에서 파이토치로 논문 발표가 엄청 많다.. 거의 90% 정도 ? 사실 요즘은 큰 차이는 없지만, 예전에는 텐서가 구현이 조금 힘들었는데 그때 몰렸다고 한다 2. 논문들 구현한 곳인데 https://paperswithcode.com Papers with Code - The latest in Machine Learning Papers With Code highlights trending Machine Learning research and the code to implement it. paperswithcode.com 여기서도 파이토치 굉장히 많이 늘어나서.. 3. 허깅페이스에도 파이토치가 압도적이니 압도적.. 4. 그래도 텐서플로우가 구글거니까 구글에서 나오는건..
1. 딥러닝 프레임워크와 기존의 ml 과 다른건 연산량 잘라가는 딥러닝 모델의 스펙은.. 웬만하면 수십억개 물론 경우에 따라서 다르지만 연산량은 어마어마하다 2. 성능이 안나온다 , 데이터가 부족해서? 더이상 쓸 방법이 없을떄,, 의심해보곤 하는데 학습시켜야 할 파라미터가 많으면 당연히 학습 시킬 데이터도 많은 것이다 3. 결국 데이터 연산량이 많다 ! 수학적으로 풀기 힘든 문제들을 해결하기 위해 딥러닝을 사용하는데 ... 텍스트, 사운드, 이미지 1960년대 나왔던 아이디어가 2014년 쯤 부흥하게 된 이유도 .. 연산 성능의 개선 그리고 분산 ( 병렬 / 동시 ) 처리의 개념으로 가능해짐 CPU의 ALU 가 당연히 성능이 좋고, GPU는 그에 비해서 부족하다 원래 graphic unit은 렌더링 하는..
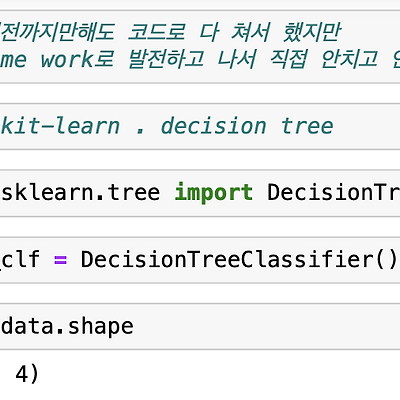 머신러닝과 싸이킷 - 런 패키지
머신러닝과 싸이킷 - 런 패키지
** 민형기 강사님 강의를 기반으로 작성했습니다 ** 머신러닝은 명시적으로 프로그래밍하지 않고도 컴퓨터에 학습할 수 있는 능력을 부여하는 학문 ( Arthur Samuel ) ** 과거 데이터로부터 얻은 경험이 쌓여감에 따라 주어진 태스크의 성능이 점점 좋아질때 컴퓨터 프로그램은 경험으로부터 학습한다고 할 수 있음 > 명시적인 프로그램에 의해서가 아니라, 주어진 데이터로부터 규칙을 찾는것, 기계가 하는 것 > 머신 러닝 ( machine learning ) * Scikit - learn > 2007년 구글 썸머 코드에서 처음 구현 , 대중화까지는 오래 걸렸음 > 2015 ~ 2016 쯤에 지금처럼 자리잡게 됨 > 원래는 교수/랩 마다 분위기가 조금씩 달랐음 > 현재는 파이썬에서 가유명한 기계 학습 오픈 ..
 세부 수준 식 ( Level of Detail )
세부 수준 식 ( Level of Detail )
{Include [차원1],[차원2],[차원3]... :sum([측정값])} * Include : 화면에 포함되지 않은 특정 차원을 포함하여 결과를 계산 * Exclude : 화면에 포함된 특정 차원을 제외하여 결과를 계산 * Fixed : 화면에 상관 없이 특정 차원을 고정하여 결과를 계산 * { include : sum([매출]) > 결과는 단일 최대값이 아닌, * exclude 표현식 : 해당 차원을 제외하고 집계함 > 대분류 > 중분류에서 exclude를 중분류 수준에서 하면, 대분류의 집계값이 나온다 > exclude 중분류한 결과는 대분류 : 중분류 수준의 매출들의 총합과 같음 * Fixed : 행의 데이터가 대분류 수준의 차원이면 , fixed 대분류와 중분류 중에서 대분류 ..
 날짜 함수 , Date
날짜 함수 , Date
* Datepart : 지정한 날짜를 구분해주는 함수 > datepart('구분 : year, quarter, week, month, day , weekday, [날짜 data] ) > 요일은 어떻게 지정되는 걸까? * Datetrunc : 날짜 형태를 유지한 채 값을 반환 ( 드릴 다운 ) 됨 > 반면 datepart는 값을 카테고리로 반환 -> 모든 기간 동안 1일의 매출 ( 예시 ) * Datediff : date difference 의 줄임말로, 날짜 간 차이를 계산하는 함수 > 예시에서는 두개의 날짜 칼럼간의 차이 ** 선택 시기 까지의 자료만 보여준다 * MTD : month to date , 선택한 일자 까지의 해당 월 자료 *QTD : quarter to date , 선택한 일자 까지의 해..
 문자열 함수 Contain / Replace / Split / Upper
문자열 함수 Contain / Replace / Split / Upper
* Contains : 원본 문자열에, 찾고자 하는 문자열이 있는지 bool형으로 반환해주는 함수 > 영어 기준으로 소문자, 대문자가 데이터에 어떻게 나와있는지 모르기 때문에 upper 함수로 대문자로 변환하는것도 방법이다 * Replace: 친숙한 놈 > replace(문자열, 교체할 부분, 대체할 문자열) > upper한 문자열을 replace하면 그대로 upper case로 출력됨.. * Split : 많이 보던거 .. 동일하다 > split(원본문자열, 구분기호, 슬라이스 된 단어의 몇번째 것을 가져올 것인지 ) * 엑셀처럼 Left 나 Right 함수 이용해보좌
 Primary 함수 Look up , Window
Primary 함수 Look up , Window
* Look up 함수 : 현재 행 기준으로 , offset(지정한 정수만큼의 거리) 만큼 떨어진 행에 대해서 결과를 반환하는 함수 * lookup(식,offset) > 현재 행으로부터 -1만큼 떨어진 행의 값을 가져오겠다 ( 한칸씩 밀림 ) > 당연히 반대로 양수 1을 하게 되면, 다음 연도의 자료를 참조할 것이다 > 테이블 기준 ~ 대비 차이를 계산할 수도 있으나, 이는 사실 퀵 계산(차이)로 더 빠르게 가능하다 * Window : 특정 범위를 지정하여 계산할 수 있는 함수 > Window_Sum > Window_avg : window 함수의 특성을 활용해서 이동평균을 구해보자 ( 퀵으로 가능하지만 직접 만들어볼 수 있다 ) > 전단계 3개와 현 단계 0번째, 즉 4개의 평균을 이동하면서 구한다 > ..
 태블로 거리함수 실습 중 참고할 만한 사항들 (기록용)
태블로 거리함수 실습 중 참고할 만한 사항들 (기록용)
1. 주/시/군 등 지역 명칭 데이터를 지리적 역할로 변경해서 시트에 넣을 경우, 임의적으로 경도/위도가 생성됨 -> 지도 히트맵은 이걸로 2. 맵 조정 옵션 / 백그라운드 레이어 조정 옵션으로 경계선 등을 없앨 수 있음 3. 일정 거리 내에 주소들이 있는지 확인하려면, 두 메이크 포인트 사이의 거리를 distance 함수로 구한 뒤 , 다시 case 함수에 넣어주어서 bool 형식으로 계산 식을 제작한다. 4. 그 결과를 count 해준다 5. 범위형으로 매개 변수 ( 거리 ) 편집 하기 6. makepoint는 위도 경도 정보를 가지고 지도에 위치를 표시해주는 기능을 가지고 있다 7. 버퍼는 makepoint와 반경 그리고 단위로, 지도에 위치 기준으로 원을 그려주는 기능이다 8. 다음은 지도에 한번..
 Primary 함수 Running , Total
Primary 함수 Running , Total
** Primary 함수 : 함수 내에 다른 함수가 포함된 함수 * Running 함수 : 현재까지 주어진 식의 누계에 대한 연산을 반환하는 함수 * Running - Running_sum > 결과적으로 누계와 동일하다 - Running_avg - Running_count - Running_max - Running_min * Total : 총 합계를 구하는 함수 > total과 sum 함수도 같은 결과가 나오고 있다
녹색은 어디서든 비슷한 사용방법 1) 숫자 함수 2) 문자열 함수 3) 날짜 함수 4) 유형 변화 5) 논리 함수 ( If .. ) 6) 집계 함수 ( count .. ) 7) 통과 함수 ( RAQSQL ) 8) 사용자 함수 9) 테이블 계산 함수 10) 공간 함수 11) 예측 모델링 함수 12) 추가 함수
 계산된 필드 ( 연산자, 논리함수, 매개변수 )
계산된 필드 ( 연산자, 논리함수, 매개변수 )
** 계산된 필드란? > 데이터 원본에 없는 필드를 새롭게 만드는 것 !!! 1) 연산자 > 함수, 필드, 매개변수 등을 연결하고 계산하여 새롭게 값을 만들 수 있는 요소 > 계산된 필드 생성 ( 데이터를 기준으로 만들수도 있고, 좌측 상단에서 전체 기준으로 계산된 필드 생성 가능 ) > 간단한 함수 기능과 연산자로 '계산된 필드' 항목 만들기 > KPI 들을 선정하고 , 생성된 지표들을 모두 시트에 나타낸 모습 함수 > 새로운 계산식을 적용하기 위해서 사용 2) 논리 함수 > if 나 case 함수는 end 로 닫아줘야 에러가 발생하지 않는다 > if 문을 사용한 경우 > 자동적으로 뷰에서 필터 기능을 할 수 있다 > 숫자 사이에 '콤마 , ' 는 인식하지 못한다 > 계산문에 //로 해당 행을 이스케이..
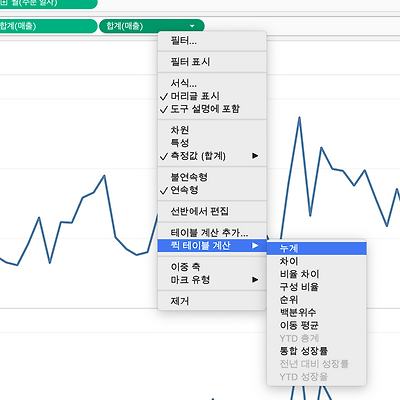 퀵 테이블 계산
퀵 테이블 계산
** 퀵 테이블이란? > 자주 사용되는 계산식들을 쉽고 빠르게 몇번의 클릭으로 계산하기 위해 지원되는 기능 > 10가지 정도의 퀵 테이블 계산을 지원한다 1) 누계 / 차이 누계 > 행 테이블 우클릭 > 퀵 계산 > 이중축 사용 > 색상변경 차이 : 전 자료 대비하여 증감을 표시 첫 번째 자료는 이전 자료가 없기 때문에 null 값이지만, 우클릭 후 표시기 숨기기를 통해서 표시를 숨길 수 있다 또한 마크 > 기준 ( 이전, 다음 ) > 등으로 차이를 계산할 기준을 변경해줄 수 있다 2) 구성비율 / 순위 * 구성 비율 측정값 우클릭 > 테이블 계산 편집으로 > 특정 차원만 계산이 가능 * 순위 > 또, 각각 분류에서 우측과 같이 ( 테이블 순위 - 전체순위 , 패널 순위 - 카테고리 내 순위 ) 각각의 ..