Packages - Pandas 본문
************************************************************************************************************
INDEX
** 판다스 패키지란 ?
** 판다스의 기본 데이터형들
** 위치에 따른 인덱스,칼럼 추출
** 조건에 따른 인덱스,칼럼 추출
** del과 Drop
** 데이터 프레임 병합 ( merge, concat, join )
** 편리한 함수들
************************************************************************************************************
** 판다스 패키지란 ?
** pandas로 csv, 엑셀 파일 읽기 : pandas ( powerful Python data analysis toolkit )
> 파이썬에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
> 단일 프로세스에서 최대 효율
> 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
> 누군가는 스테로이드를 맞은 엑셀로 표현함
< 기본적인 모듈 사용 방법 >
import module -> 모듈을 사용하곘다
import module as md -> 모듈을 사용할 건데, 앞으로는 md라는 이름으로 부르겠다 / alias
사용 : md.functioin
from module import function -> 모듈에 포함된 function만 사용하겠다
사용 : function
MAC OS 에서는 finder에서 command + option + c(copy)로 파일의 경로 복사해오기 가능 ( 경로 지정 시 편리 )
** pandas function reference 공식 사이트 참고
https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
pandas.read_excel — pandas 1.4.1 documentation
Additional strings to recognize as NA/NaN. If dict passed, specific per-column NA values. By default the following values are interpreted as NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IN
pandas.pydata.org
** 판다스의 기본 데이터 형들
** pandas의 데이터형을 구성하는 기본은 Series이다
> Series는 index와 value로 구성되어 있으며, 한 가지 데이터 타입만 가질 수 있습니다
> dtype= str , float64 등 지정할 수 있고
> 딕셔너리 형태로 {"key":"value"} 를 넣어주거나
> np.array([1,2,3]) 등으로 행렬을 넣어줄 수도 있다

** pd.date_range 는 날짜를 다룬다
> range는 시작 일자 부터 ~ periods만큼의 시간까지 순차적으로 일자를 생성해준다

** pd.DataFrame은 가장 많이 사용하는 데이터 형이다
> index와 columns value로 구성되어 있다
value에는 np의 random.randn함수의 값이
index에는 위의 pd.date_range함수의 값이
column에는 a b c d가 지정되어 있음

** 위치에 따른 인덱스,칼럼 추출
** df.head() , df.tail() 위/아래로부터 행 5개를 읽어옴

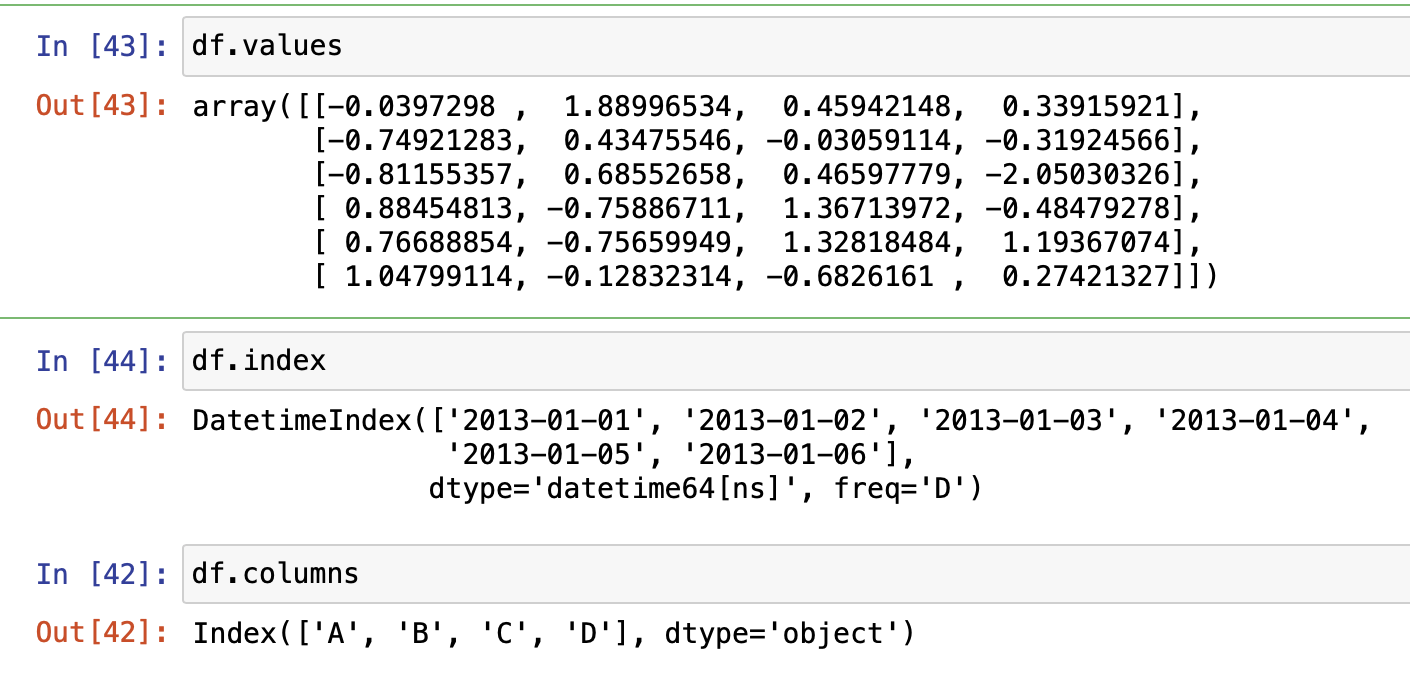
** df.values : value들을 출력
** df.index : index를 출력
** df.columns : column들을 출력
** df.info()
> 데이터 프레임의 기본 정보 확인
# 각 칼럼의 크기와 기본 데이터 형태(타입)를 확인할 수 있다


** df.describe()
> 기초 통계정보들을 확인할 수 있는 함수
** df.sort_values(by="기준칼럼",ascending=True) # 오름차순/ 내림차순 옵션
> 데이터 정렬 , 특정 칼럼 데이터 정렬
**특정 칼럼이나 인덱스만 읽기
> df.coulmn_name
> df["칼럼명"] ( 인덱스를 사용하는 경우 )
> df[0:3] 행 번호를 지정해서 읽기
(오프셋 인덱스 개념을 따라간다 [n:m] -> n 부터 m-1까지 ) , 그러나 인덱스나 칼럼의 이름으로 slice하면 끝도 포함
> df["인덱스이름":"인덱스이름"]
** 특정 위치의 행렬을( 인덱스 - 칼럼 )지정해서 읽기 ( 행과 열 모두 지정하는 옵션 )
> loc for location , iloc for interlocation
df.loc["인덱스명",["칼럼명","칼럼명"]]
df.loc[:,["칼럼명","칼럼명"]] ( 이 경우 인덱스는 전체 )
df.iloc[3:5,0:2] ( 3부터 5-1번행까지와 0부터 2-1번 열을 읽어라 )
> 숫자로만 접근하는 개념.
** 조건에 따른 인덱스,칼럼 추출
** 조건 지정하기
df[df["A"]>0]
> df에서 df["A"] A컬럼에서 0 이상인 값들만
df[df>0]
> 범위를 정하지 않고, 전체에서 0 이상인 값들을 표시해라
> 0 미만의 값은 NaN처리가 된다
* 특정 요소가 있는 행만 선택
> df["칼럼"].isin(["value"])
> 특정 칼럼에 특정 값이 있는지 bool형으로 출력해준다
> 여러 값들도 조회해볼 수 있다


df[df["칼럼"].isin(["value"])]
위의 조건을 df[조건]으로 지정하면 조건에 맞는 자료가 출력된다
** 특정 컬럼 제거 del 과 drop
del df["column"]
df.drop(['column1','column2'],axis=1)
> axis = 0 option is default, 가로 -> 그러니 컬럼이 아니라 인덱스 값으로 행을 제거하는 것
> axis = 1 해야 세로 ( 컬럼을 제거한다 )
** 컬럼 추가
df["column_name"] = 길이에 맞게 자료를 설정
> 기존에 자료가 있다면 수정
> 기존에 없던 컬럼명이면 추가

** apply(함수) : 함수를 적용해준다 응용 방법이 많다
df.apply(np.cumsum)
df["column_name"].apply(sum) > 컬럼 여러개도 적용할 수 있다
.apply(function) 에 userdef func와 람다 함수도 당연히 적용 가능
** 인덱스 지정하기
> df.set_index()
> 선택한 컬럼의 값들을 데이터 프레임의 인덱스로 지정
** Pandas에서 데이터 프레임 병합은 3가지 방법이 있다
> 데이터 셋이 클수록 오류가 생길 수 있어서 기본을 잘 숙지하고 확인해라
pd.concat() , pd.merge(), pd.join()
*merge 이용해서 데이터 병합하기
> 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
> 기준이 되는 키 값은 두 데이터 프레임에 모두 포함되어 있어야 한다


> 기본 옵션은 how = inner 로 되어 있다 . 이너조인은 공통 키값만 병합한다 / 반대인 외부 조인은 모든 키들을 병합한다


> 레프트 / 라이트 조인 옵션

** 버전 관련
> 버전에 따라 문법이 다르다
> 인터넷에서 확보하거나 유포하고자 하는 소스코드가 다를 수 있으니 확인해야 함
'파이썬 > 파이썬 기본' 카테고리의 다른 글
| Pandas - .pivot_table (0) | 2022.02.23 |
|---|---|
| Packages = Matplotlib (0) | 2022.02.23 |
| 예외, 예외처리 방법들 (0) | 2022.02.03 |
| 텍스트 파일 다루기 (0) | 2022.02.03 |
| 패키지 이용과 site-packages 경로 (0) | 2022.02.03 |



