SSD : Single Shot MultiBox Detector 본문
세그멘테이션 업무를 하고 있는 와중에 SSD + regnetx + fpn 방식으로 구성한 네트워크가 있는데 잘 모른다...
SSD 스터디가 필요함.
기존 스터디한 네트워크는 FPN, U-Net, Deeplabv3~3+, R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN 으로, 이놈들을 기준으로 아만보를 시전할 예정이다ㅜㅜ.
SSD: Single Shot MultiBox Detector ( 2016 ) - ECCV
Search | arXiv e-print repository
Showing 1–30 of 30 results for author: Berg, A C arXiv:2304.02643 [pdf, other] cs.CV cs.AI cs.LG Segment Anything Authors: Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexand
arxiv.org
0) Abstract
single deep neural network를 사용하여 이미지의 물체를 검출하는 방법을 제시한다.
-> single-stage detector
< 참고 >
$ 1(Single)-Stage Detecor와 2-Stage Detector

Region Proposal과 Classification이 동시에 한 네트워크에서 이루어짐.
Region Proposal Network가 있고, Classification Network가 있어 서로 다른 네트워크 branch가 다른 일을 담당함.
Bounding box의 출력 공간을 이산화하여(discretize) feature map 위치별로 다양한 종횡비와 크기를 가진 박스들로 분할한다.
-> 마치 Faster R-CNN에서 selective search를 대체하여 RPN 사용하였을 때 anchor generator 역할처럼 보임.
예측시에는 네트워크가 각 박스마다 카테고리 별로 점수를 생성하고, 검출 대상의 형태(shape)에 맞게 수정(adjustment)하는 과정이 존재한다.
추가적으로, 네트워크는 다양한 해상도(resolution)을 가진 복수의 feature map에서의 예측 결과를 종합하는데, 이는 다양한 크기의 검출 대상을 검출하기 위함이다.
-> Deeplabv3에서 다양한 크기의 dilated 필터를 사용한 뒤 합치는 ASPP(Astrous Spatial Pyramid Pooling)등에 상응하는 작용으로 보인다.
하지만 SSD는 검출 대상에 대한 제안?을 하는 방법들에 비해서 상대적으로 단순한데, 왜냐하면 SSD는 추천 생성 및 후속 픽셀 (subsequent pixel)?? 혹은 feature resampling stages를 제거하고 모든 컴퓨팅을 단일 네트워크에서 수행하기 때문이다. 이러한 이유로 SSD가 훈련이 쉽고, detection component가 필요한 시스템에 통합하기에 직관적인 것이다.
PASCAL VOC, COCO, ILSVRC 데이터 셋을 통해 검증한 바, SSD는 추가적으로 object proposal step을 하는 방법에 비해 빠르며, 성능도 견주어볼 수 있다. 성능도 300*300 input에서는 74.3% mAP에 59FPS가 나오며, 다른 single-stage method와 비교해서도 더 작은 입력 이미지 크기에서 더 나은 accuracy를 보인다.
1) Introduction
현재 짱짱인 State-Of-The-Art 녀석들은 ( ~ 2016년 기준 ) 다음과 같은 접근 방법의 변형들이다. 바운딩 박스를 예측하고, 각 박스의 픽셀이나 feature를 resample하고, 좋은 분류기를(high-quality classifier) 적용한 것.
이러한 파이프라인은 전반적으로 디텍션 벤치마크를 씹어먹었고, 현재(2016 당시) PASCAL VOC, COCO, ILSVRC detection에서 모두 최고의 성능을 보여주었던, Faster R-CNN의 Selective Search를 기반으로 한 것이나, Faster R-CNN보다 deeper feature를 사용한 것들이다.
# 본인은 7FPS 정도인 네트워크면 그래도 사용할 만하다고 생각하지만, 엣지 디바이스에서 real-time-inference 하는데 20~30 FPS는 나오면 좋긴 하다. 논문 저자도 그렇게 생각한 부분인 것 같다.
그러나 이런 짱짱녀석들은 정확성은 높았으나, 임베디드 시스템이나 고성능 하드웨어에도 적용하기에 연산이 너무 과도했고, 실시간 어플리케이션에 적용하기도 너무 느렸다. 심지어 디텍션 속도를 SPF(Second Per Frame)으로 측정하는 경우도 있었다. 가장 빠르고 정확성이 높은 Faster R-CNN은 7FPS정도였다.
어쨌든 위의 디텍션 파이프라인을 건드려서 더 빠른 detector를 만들기 위한 시도가 많이 이루어졌었지만, 현재로서는 속도를 많이 줄이면 그에 상응하여 detection accuracy가 줄어들었다.
SSD는 pixel resample이나 bounding box hypothese 없이 가장 정확하고 빠른 첫번째 네트워크라고 소개함.
59 FPS with mAP 74.3% on VOC2007 test, vs. Faster R-CNN 7 FPS with mAP 73.2% or YOLO 45 FPS with mAP 63.4%
SSD가 사용하는 방법은, 사실 저자가 처음 시도한 건 아니라고 한다.
나머지 내용들은 거의 동일한 내용에 대해서 말하고 있으니 생략.
2) The Single Shot Detector
2장에서 다루고 있는 내용은 다음과 같다.
2-1) SSD framework
2-2) training methodology
2-3) data-specific model details and experimental results
2-1) SSD Framework
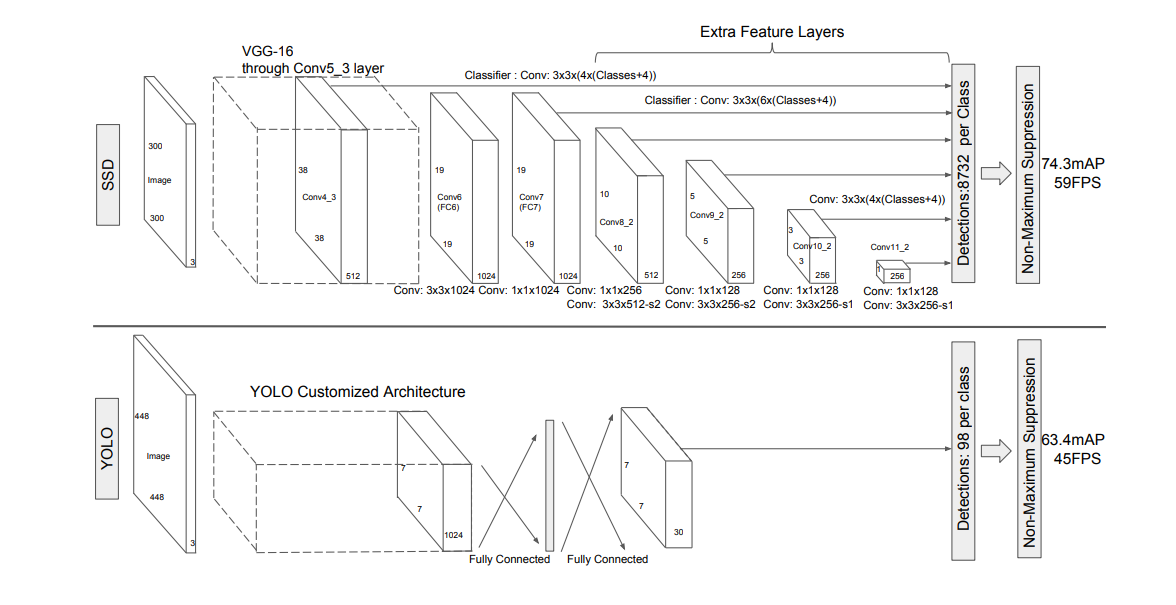
- 300 *300 or (512 * 512 ) 이미지 -> backbone network ( VGG-16 ) -> 38 * 38 * 512로 축소. -> 이후 conv layer 통과하며 feature layer 생성 -> box 생성 및 nms -> 결과
- 깊이와 크기가 다른 각각의 conv_layer 마다 feature layer들이 output으로 출력됨.
- 본문의 "yielding (c + 4)kmn outputs for a m × n feature map" 의 내용은 다음과 같다.
- k (클래스 개수) * mn (feature map 크기 = 픽셀 개수) * ( c + 4 )
- c = confidence score, 4 = box offsets ( 좌표 )
- Conv4_3은 ( 38 * 38 ) * 512 의 output이며 3*3 conv를 통과함. -> output은 ( 38 * 38 ) * 4 * ( c + 4 ) 가 출력됨. c는 배경 클래스로, 다른 클래스 개수 + 1. 예시에서 클래스가 1개, 단일 클래스이면 c = 2. 박스 개수는 38 * 38 * 4 = 5776
- 만약 클래스가 1 개, c =2 라고 하면..
- Conv7 역시 마찬가지로 ( 19 * 19 ) * 1024 -> (19 * 19) * -> 19*19*6개의 박스 생성. output은 19*19*6*(c+4)
- Conv8_2: 10×10×6 = 600 박스 개수 (6 boxes for each location) -> output 개수= 10×10×6×6(6=c + box 좌표 x,y,b,h)
- Conv9_2: 5×5×6 = 150 박스 개수 (6 boxes for each location) -> output 개수= 5×5×6×6(6=c + box 좌표 x,y,b,h)
- Conv10_2: 3×3×4 = 36 박스 개수 (4 boxes for each location) -> output 개수= 3×3×4×6(6=c + box 좌표 x,y,b,h)
- Conv11_2: 1×1×4 = 4 박스 개수 (4 boxes for each location) -> output 개수= 1×1×4×6(6=c + box 좌표 x,y,b,h)
- Total 박스 개수 = ({38*38*4}+{19*19*6} + {10*10*6} + {5*5*6} + {3*3*4} + {1*1*4}) = 8732
- Total output 노드 개수 = 8732 * ( 2(클래스+1) + 4(박스 offset) )
2-2) Training methodology
* Choosing scales and aspect ratios for default boxes
Choosing scales :
네트워크 안에서 다른 크기의 feature map들의 receptive field size는 서로 다르다. SSD에서는 박스의 수용장 크기에 맞도록 반응할 필요 없이, feature map의 개수에 따라서 박스의 scale이 반응하도록 디자인하였다.
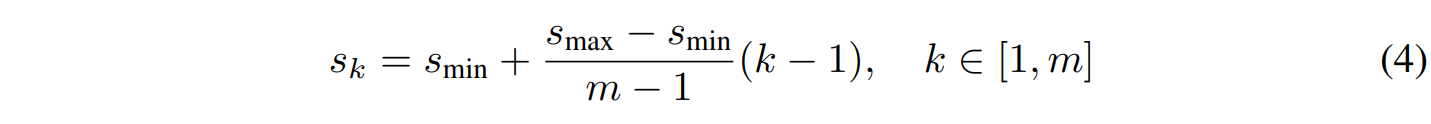
수식을 보면, m개의 feature map이 있을때, k번째 feature map의 스케일 Sk는 서로 등간이다. 우선 최대 스케일 Smax - 최소 스케일 Smin 값이 전체 feature map 개수 -1로 나뉘고(Smin + ~ 이기 때문에 해당 값을 제외 ), 이후 그 값이 몇 번째이냐에 따라서 k가 곱해지기 때문이다.
따라서 m =6. m=7 일때 각각 S1~6, S1~7은 다음과 같이 등간이다. 원문에서는 이를 all layers in between are regularly spaced 라고 표현하고 있다.
S1~7 = [0.2, 0.316, 0.432, 0.548, 0.664, 0.78, 0.9] m=7, len=7
S1 ~6= [0.2, 0.34, 0.48, 0.62, 0.76, 0.9] m=6, len=6
Choosing aspect ratios :
ar(aspect ratio) = [ 1, 2, 3, 1/2,1/3 ]
K = [1 ~ m ]
각각의 default box의 너비와 높이는 다음과 같다.
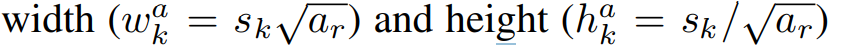
default box는 feature map location마다 ar의 수 만큼 생성되며, 총 m * ( ar + 1 ) 개 생성된다.
+ 1개 더 생성되는 이유는, aspect ratio ar = 1일때 , ( ar =1 , Sk = S'k )인 박스를 추가로 생성한다. S'k는 현재 스케일과 다음 스케일의 값을 곱한 후 제곱근을 취한 값이다.
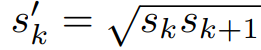
ex) m=5, feature location의 scale(k)= 3 이고, aspect ratio가 1일 때 추가로 생성되는 default box의 scale 값은 다음과 같다.
S'3 = sqrt(S3 * S4) -> sqrt( 0.55 + 0.725 ) = 1.129
S3 = 0.2 + ( 0.7 / {5-1} ) * (3-1) = 0.2 + (0.175)*2 = 0.55
S4 = 0.2 + ( 0.7 / {5-1} ) * (4-1) = 0.2 + (0.175)*3 = 0.725
마찬가지로 전체적으로 생성되는 default box는 ( 너비와 높이가 다름 ) 다음과 같다.
| ar = 1 | ar = 1 ( S'k ) | ar = 2 | ar = 3 | ar = 4 | ar = 5 | |
| m = k = 1 | S1 | Sk <- S1S2 | S1 | S1 | .. | .. |
| m = k = 2 | S2 | Sk <- S2S3 | S2 | .. | .. | .. |
| m = k = 3 | S3 | Sk <- S3S4 | S3 | .. | .. | .. |
| m = k = 4 | S4 | Sk <- S4S5 | S4 | .. | .. | .. |
| m = k = 5 | S5 | Sk <- S5S? | S5 | .. | .. | S5 |
즉, ar = 5 개이고, per feature location은 m개 이지만, ar이 1일때 per feature location에서 default box가 한 개씩 더 생성되니, 총 (ar +1) *m 개 = 즉 6개의 default box가 생성되는 것이다.
만약, ar 을 다양하게 구성하지 않고 [ 1, 2, 1/2, 1/3 ] 4개로 구성하였을 때는 5개(4+S'k1)의 default box가 각각의 feature location에서 생성될 것이다.
* Select box location
default box들은 scale과 aspect ratio에 따라 생성되며, 한 스케일에서는 aspect ratio + Sk'R까지 6개의 default box들이 생성되는데, 그 박스의 중심 위치는 다음과 같이 생성된다.
( box width와 height 역시 scale 값이니, 크기 값이 1이 되지 않는다고 혼동하지 말자 )
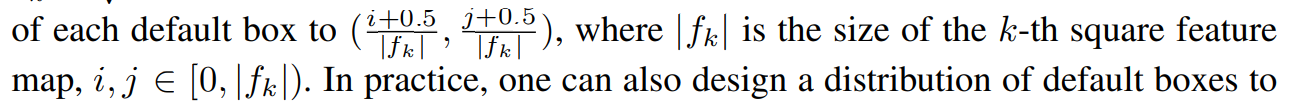
|fk|는 k번째 feature map의 크기이다. 그리고 i와 j는 feature map 크기에 따라서 달라지는 인덱스의 값이다.
예를 들어, |fk|가 8*8 사이즈의 feature map이면, i와 j의 인덱스는 다음과 같으며, location 역시 64곳 생성된다.
| i , j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 0 | 0,0 | 0,1 | 0,2 | 0,3 | 0,4 | 0,5 | 0,6 | 0,7 |
| 1 | 1,0 | .. | .. | .. | .. | .. | .. | .. |
| 2 | 2,0 | .. | .. | 2,3 | .. | .. | .. | .. |
| 3 | 3,0 | .. | .. | .. | .. | .. | .. | .. |
| 4 | 4,0 | .. | .. | .. | .. | .. | .. | .. |
| 5 | 5,0 | .. | .. | .. | .. | .. | .. | .. |
| 6 | 6,0 | .. | .. | .. | 6,4 | .. | .. | 7,6 |
| 7 | 7,0 | 7,1 | 7,2 | 7,3 | 7,4 | 7,5 | 6,7 | 7,7 |
64곳의 location 중 i =2, j = 3 일때 생성되는 박스의 중심은 다음과 같다.
Bc = { (2+0.5)/8 , (3+0.5)/8 } , Bc = { 0.3125, 0.425 }
Bc = { (7+0.5)/8 , (6+0.5)/8 } , Bc = { 0.9375, 0.8125 }
--> 이 부분은 왜 위와 같은 수치가 나오는 것인지 잘 이해가 되지 않는다... ㅜㅜ
code implementation을 보면 ( box center에 대한 코드가 아래 부분밖에 없음 ) 다음과 같다.
최종 feature map 의 box가 원본 대비 얼마나 줄어들었는지 판단하고,
박스가 있을 수 있는 input image의 위치를 그리드화 한 뒤,
해당 영역에 대해서 모든 중심위치를 만드는 것.
이후 box 크기만큼 더하고 빼줘서 [x,y,w,h] 방식으로 결과가 출력된 뒤 NMS를 실행한다.
정확히 SSD 논문의 모든 메소드가 구현된 것은 아닌 것 같은데, 이 부분을 제대로 이해하기 위해서는 구현 코드를 더 찾아봐야 한다. 이 파트를 다루는 자료들이 많이 없다...
우선, 이미지 너비와 높이 / feature map의 너비와 높이 -> 확장 비율을 계산하고
ex) 300 / 8
step_x = float(img_width) / float(layer_width)
step_y = float(img_height) / float(layer_height)
0.5 * step_x 부터 img_width - (0.5*step_x)까지의 값 까지 layer_width만큼의 구간으로 나누어서 간격별로 중심의 위치를 생성
ex) 0.5*27 ~ 300- 0.5*27, 8
--> 13.5 ~ 286.5 , 8씩
--> [13.5 , 21.5 , 29.5, ......270.5, 278.5, 286.5 ]
linx = np.linspace(0.5 * step_x, img_width - 0.5 * step_x, layer_width)
liny = np.linspace(0.5 * step_y, img_height - 0.5 * step_y, layer_height)
생성한 모든 중심 위치를 그리드로 표현하는 배열 생성
centers_x, centers_y = np.meshgrid(linx, liny)
centers_x = centers_x.reshape(-1, 1)
centers_y = centers_y.reshape(-1, 1)
prior_boxes = np.concatenate((centers_x, centers_y), axis=1)
prior_boxes를 각 차원별로 1번, 2*num_priors만큼 복제.
num_priors는 aspect ratio의 개수 ( 배열의 길이 )
ex) if prior_boxes = [a, b]:
then np.tile(prior_boxes, (1,2*num_priors=1)) 이면
result = [ [ a, b ]
[ a, b ] ]
prior_boxes = np.tile(prior_boxes, (1, 2 * num_priors))
* hard negative mining ( 본문 직역 아님 )
다양한 스케일과 aspect ratio를 가진 box들을 다양한 location에서 생성해냈다. 이러한 예측들을 통해 다양한 input object의 size와 shape에 대응할 수 있을 것이다. 모든 박스들을 training/inference에 사용하는 것은 cost-efficient하지 않다. 따라서 이제 이 예측들을 matching하는 작업을 수행한다. Matching은 feature map을 통해 예측한 박스와 ground truth의 IOU treshold에 따라서 정해진다.
대부분의 box들은 이 과정에서 negative sample이 된다(significant imbalance between the positive and negative samples). 이 중에서 confidence loss가 높은 순으로 정렬하여, positive와 negative의 비율이 1:3이 되도록 추출한다. 이 과정을 통해 최적화 속도를 높이고 훈련을 안정적으로 진행할 수 있다.
* loss function
전체적인 loss fucntion 은 confidence score loss와 localization loss로 이루어져 있으며, 다음과 같다.
L(x,c,l,g) = 수식 2) 3)에서 N개 만큼 더해주었던 loss를 1/N으로 나누어준 것이다.

우선 SSD의 training objective[7,8]은 아래의 방법들을 차용한 것이다.
7. Erhan, D., Szegedy, C., Toshev, A., Anguelov, D.: Scalable object detection using deep neural networks. In: CVPR. (2014)
8. Szegedy, C., Reed, S., Erhan, D., Anguelov, D.: Scalable, high-quality object detection. arXiv preprint arXiv:1412.1441 v3 (2015)
차이점으로는 Multiple object categories를 다룰 수 있도록 확장되었다.
confidence loss의 계산에 대한 부분
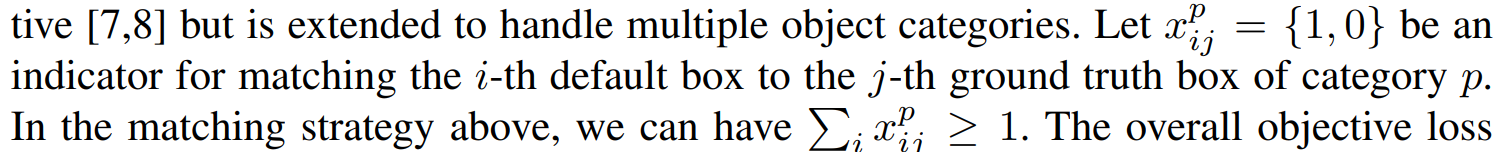
만약 한 default box와 ground truth box가 매칭되면, {1,0} -> 1 이 인디케이터 값으로 반환된다.
즉 특정 카테고리에 대해서, 생성되는 모든 default box들에 대해서 j번째 ground truth box와 매칭이 이루어졌을 경우, 인디케이터 들의 값이 모두 더해져 >= 1 일 수 있다. 이를 통해 어떤 한 박스에 대해서만 confidence loss를 계산하는 것이 아닌, 모든 박스에 대해서 각자 다른 class의 confidence Loss를 계산할 수 있다.
다시 말해 한 박스에서 다중 카테고리에 대해서 동시에 예측할 수 있는 유연성을 가지게 된다.
수식 3)을 참고하면, positive sample에는 N개의 box가 있을 수 있고, 그 박스의 index는 그 중 하나인 i이다. matching되는 ground truth 역시 j이다. 그러면, 해당 i박스에는 여러 개의 클래스 p가 존재할 수 있다. 만약 인디케이터가 1이라면 계산을 수행하고, 0이라면 수행하지 않는다. 이런 식으로 모든 박스에서 존재하는 클래스에 대해서 softmax를 취해 더해지는 것이다.
localization loss의 계산에 대한 부분 ( bounding box regression )
수식 2)를 참고하자. positive sample중 하나인 i에 대해서 매칭되는 j번째 ground truth간의 계산이다. 각각의 positive sample에서 offset과 박스 정보를 가지고 center x, center y, w, h 를 구할 수 있다.
이때 xk ij는 ( l - g )의 smooth L1 loss이며, m이 cx, cy, w, h 어떤 원소인지에 따라서 계산 방식이 각기 다르다.
최종적으로 cx,cy,w,h에 대한 loss들이 각각의 성분에 대해서 계산되어 합해진다.
** Smooth L1 loss
smooth L1 loss는 l과 g의 차이가 클 경우 L1 손실을, 작을 경우는 L2 손실을 사용하는 것이다. L1은 절댓값, L2는 제곱값의 차이이며, L2이 제곱값을 통해 오차를 측정하기 때문에 큰 값이 더 큰 차이를 발생한다. 따라서 이상치에 더 민감하게 반응한다고 할 수 있다. 반면 L1 loss는 이상치에 더 강건하다. 다만 L1 손실은 상수이기 때문에 미분 불가능한 지점이 존재한다. Smooth L1 loss를 사용하면 그래디언트의 변화를 완화할 수 있다. 그 형태는 아래 그림을 통해 확인할 수 있다.
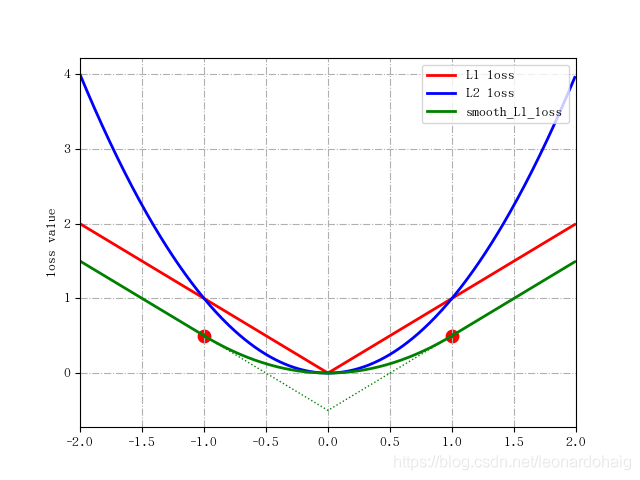
SSD에서는 Faster R-CNN의 smooth L1 loss를 사용하였고, 확인해보니 L1 ~ L2 의 B값은 1인것 같다.
* Data augmentation
SSD는 smaller object에 대해서 퍼포먼스가 좀 낮게 나온다.
"zoom in operation" 을 sampling 할 때 사용하여 데이터를 증강함.
전체 원본 입력 이미지를 사용해서, 탐지 객체와의 자카드 유사도가 0.1, 0.3, 0.5, 0.7 혹은 0.9이면서 원본 이미지 크기의 [ 0.1 ~ 1 ], 종횡비 [1/2 ~ 2 ] 범위의 패치를 생성한다. 해당 패치들이 겹치는 부분에 ground truth box가 있으면, 해당 패치들의 영역만 사용한다. 0.5의 확률로 horizontal flip을 가하고, 다음의 photometric process를 거쳤다고 한다. ( Some Improvements on Deep Convolutional Neural Network Based Image Classification , Andrew G. Howard )
- translation invariance에 대해서는 Random crop하는 부분과 multiple scales and view라는 관점은 같고, 같은 맥락에서 SSD에서 패치를 사용함.
- reflection invariance 때문에 horizontal flip을 사용함. 이 부분도 위에서 적용됨.
- 나머지는 contrast, brightness, color, random lighting noise -> 이 부분은 레퍼런스가 (ImageNet Classification with Deep Convolutional Neural Networks, A,Krizhevsky., G,E.Hinton. et al.).
Data Augmentation
가장 쉬운 증강 방법은, 라벨이 보존되는 변환인데 ~ 크게 두가지 방법을 사용했고, GPU가 돌아갈때 CPU에서 돌려서 computationally free한 방법을 사용한다 ~~ 로 요약된다.
1. 여기서도 generating image translation(패치)과 horizontal reflections를 사용. 비슷한 개념으로 SSD도 사용.
2.RGB channel의 밀도를 변환하는 방법. PCA throughout 데이터셋, 발견한 주성분의 배수를 원본 이미지에 더해준다.
이때 추가되는 값은 고유값에 해당하는 크기의 랜덤 변수를 mean=1, std=0.1인 가우시안 분포에서 추출한 값이다.
< GPT의 설명 >
따라서 각 RGB 이미지 Ixy의 (RGB) 픽셀에 다음 수량을 추가합니다:
Ixy = [IRxy, IGxy, IBxy]
[p1, p2, p3][α1λ1, α2λ2, α3λ3]T --> 1*3 3*1(1*3의 T) -> 1*1 값이 IRxy ~ IBxy에 더해진다는 것?
여기서 pi와 λi는 각각 RGB 픽셀 값의 3 × 3 공분산 행렬의 ith 고유벡터와 고유값이고, αi는 이전에 언급한 랜덤 변수입니다.
-> 고유벡터만 PCA 결과이고, 가중치 α는 1,2,3 모두 거의 조금차이나게 곱해줘서 적용한다는 뜻.
각 αi는 한 번만 그립니다. 특정 훈련 이미지의 모든 픽셀에 대해 그리고 해당 이미지가 다시 훈련에 사용될 때까지 동일한 값이 유지됩니다.-> 한번 뽑아서 훈련하고 redrawn된다는데, 위의 intensity alter한 기준으로 이미지를 다시 그리고, 그 이미지가 다시 활용될 경우 바뀐 이미지를 기준으로 PCA를 수행한다는 뜻인가? --> 테스트 해볼 것.
이 방식은 자연 이미지의 중요한 특성인 물체의 식별이 조명의 강도와 색상의 변화에 불변함을 근사적으로 잡아내는 것입니다. 이 방식은 top-1 오류율을 1% 이상으로 감소시킵니다.
top-1 error는, 모델이 가장 높은 확률로 예측한 클래스가 실제로 해당 샘플의 클래스와 일치하는지. 의미 있어보임.
<----- 끝 ----->
'BF 2024 > 컴퓨터 비전 관련' 카테고리의 다른 글
| PCA on RGB channel for data augmentation (0) | 2023.06.07 |
|---|
