문법과 파싱 본문
** 문법 : 문장의 구조적 성질을 규칙으로 표현한 것
** 구문 분석기 ( Parser )
> 문법을 이용하여 문장의 구조를 찾아내는 과정
> 문장의 구문 구조는 트리로 표현할 수 있다. 즉 몇개의 형태소들이 모여서 구문 요소를 이루고, 이들이 결합된 구조가 트리 구조인 것이다.

> 트리를 그릴때 문장 구조를 분석할 때 중요한 두 가지 원칙
1) Headedness Principle ( 핵내재 원리 )
모든 구조는 핵을 가지고 있어야 하며, 핵이란 병합에 있어서 두 요소 중 의미적으로 더 중요한 성분을 말한다.
2) The Principle of Binarity ( 이분지 원리 )
촘스키의 분석 방식이며, 모든 병합은 ( 병합을 요구하는 자 - 병합을 요구받은 자 ) 로 나누어진다. 따라서 모든 구조는 두 개의 구성소로 이루어지게 된다.
** 형태적 정의에서의 문법이란
Grammar is a set of rewrite rules
Ex) s -> np vp
np -> n
vp -> v np ( np -> n ) 등 문장을 형태소 단위까지 계속 rewrite할 수 있다
** 반면 context free grammar ( cfg )
N a set of non-terminal symbols -> rewrite 최종 단위
Σ a set of terminal symbols ( rewrite 의 왼쪽 )
R a set of productions or rules ( a -> b , 즉 non-terminal 과 terminal의 조합의 경우 )
-> 굉장히 중요한 제약 조건으로서, a는 반드시 non-terminal 요소가 하나 이상 존재해야 한다
-> 왜 context free 이냐? 맥락을 생각하지 않고 re-write할 수 있는 경우들을 생각하니까
S a designated non-terminal called the start symbol
** Sentence Generation ( derivation , parse tree )
start symbol ( lexicon 기준 ) 에서부터 rewrite를 하여 terminal symbols만 남을때 까지 쓰게 되면,
문장이 생성된다.
** Parsing
> terminal string의 입력과 CFG 를 가지고 CFG로 만들 수 있는 합법적인 문장인지 판단한다
-> parse tree가 생성된다
-> 잘 만들었어도 가능한 여러개(모든)의 parse tree가 생성된다
** Parsing, search space 가용 방법
1) Top-Down Parsing : starting symbol 부터 모든 룰을 적용해보며 derivation이 일어남.
그럼에도 불구하고 원하는 문장이 생성되었는지/실패하였는지 체크하는 방식.
ex) book that flight -> S - VP -> VP ( Verb + NP ) -> Verb - book , NP ( Det + Noun ) ....
+) rule 만 가지고 Rewrite를 계속 하기 때문에, 실제 actual sentence 보다 더 많은 옵션들도 탐색한다
2) Bottom-up Parsing : re-write룰에서 거꾸로 올라가는 것. terminals의 우측부터 CFG에 따라서 성분들을 합쳐가면서 올라감.
ex) book(Verb) that (Det) flight( noun < nominal ) -> Det+Nominal = NP , V + NP = VP , VP - S
+) actual sentence로 부터 시작하지만, 엉뚱한 규칙까지 탐색한다
두 방식 모두 문장이 조금 복잡해지면 backtracking에서 낭비적인(과다한) 검색량이 발생한다
*** Dynamic Programming Parsing
> array에 중간 결과를 저장해놓고 과도한 반복 작업을 방지한다 ( caching intermediate result ) , tabular parsing
> 가능한 모든 방식을 찾는다
> DPP로 O(n^3) 정도의 복잡도로 parsing 알고리즘을 만들 수 있다. n = 한 문장의 단어 수
** DPP 의 종류들
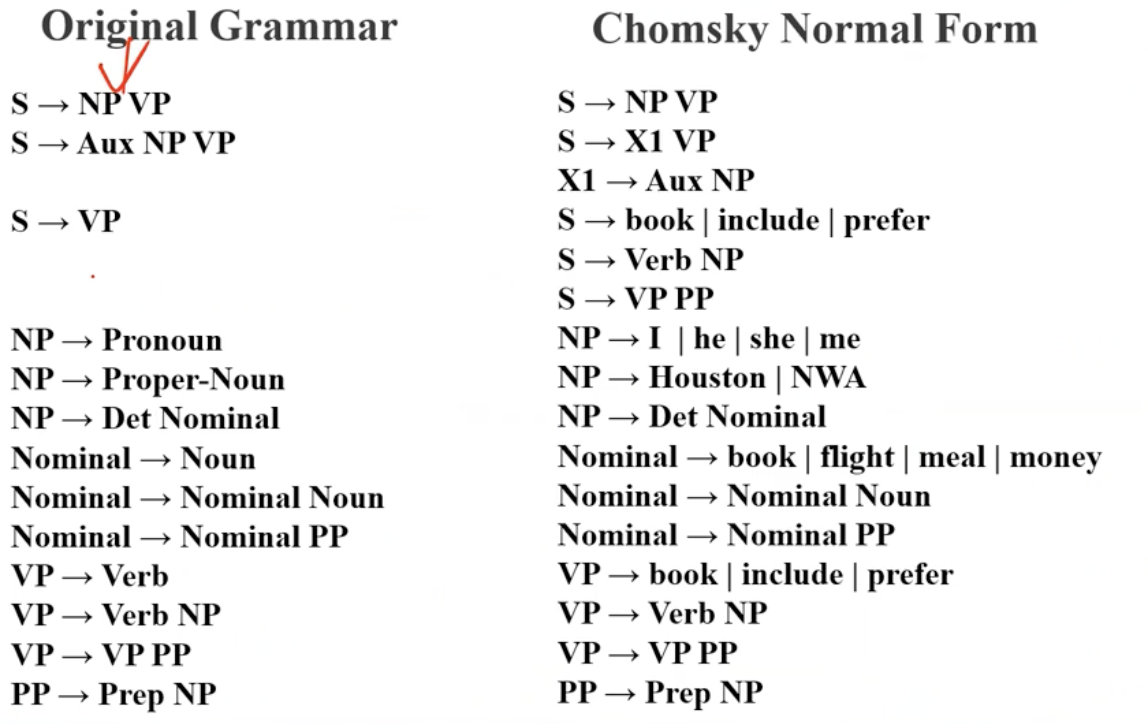
1) CKY ( Cocke-Kasami-Younger ) : 가장 간단한 파싱 알고리즘 1965년 쯤 등장 , 바텀업 방식. 문법 정규화 필요.
-> 반드시 CNF ( Chomsky normal form ) 으로 정규화 해야 한다.
( a -> b에서 b는 꼭 1개의 Terminal 이거나 max 2개 성분으로 나누어진다 ( t + nt ) or (nt + nt ) non-terminal symbol, 이분지 원리 )
-> triangular table 을 사용한다

(0,1) Book : noun 에서 부터 re-write를 거꾸로 ( bottom - up ) 하여 ( 책 Noun > Nominal, 예약하다 Verb -> VP -> S )
( 1,1) The : Det 작용 , ( 1,1 ) book the ( det 로 앞의 단어랑 결합 불가능한 경우 ) - > None
( 2,2 ) , ( 1,2 ) , ( 0,2 )
( 0, 3) 은 ( 0,1) 과 ( 1, 3) 규칙의 결합 ( Verb + NP ) = VP
...
.... (0,4) 최종 결과물 중의 S 성분들이 최종 parse tree이다
S1 = VP(Verb + NP(Det + Nominal) + PP(Prep + NP) , S2 = Verb + NP ( Det + Nominal( PP ( Prep + Nominal )))
> 총 n^2 / 2 개의 셀에 대한 계산이 필요하고 n번씩 대조를 하기 때문에, O(N^3)의 복잡도가 된다.
> 하지만 모든 가능한 parse를 다 찾는다고 가정하게 되면, 영어 문법의 특성상 N!개의 parse tree가 만들어질 가능성이 있다. 그럼 결국에는 exp해진다...
-> 절대 태보해 ( Syntatic Ambiguity .. 라는 문제.... 결국 가장 킹능성이 있는 파스 트리부터 찾아야 하는 방식대로 가게된다. )
-> CNF 에서 original grammar form 으로 변환은 쉽기 때문에, 나쁜 영향이 있는것은 절대 아님
2) Earley parser : Earley의 박사학위 논문, top-down 기준이고 문법 정규화는 필요없지만 복잡하다. 빠른 편
3) chart parsers : 파싱의 중간결과를 차트에 기록하는 방식 ( 탑 다운 , 바텀업을 섞음 ).
'딥러닝 > 자연어처리' 카테고리의 다른 글
| BERT 강의 필기 (0) | 2022.05.25 |
|---|---|
| Grammars and Parsing (0) | 2022.03.23 |
| N-gram model과 등장 배경 (1) (0) | 2022.03.23 |
| ML/DL NLP에서의 접근 방법 (0) | 2022.03.02 |
| 언어의 모호성과 해결 방법, NLP 기술의 발전사 (0) | 2022.03.02 |

